
Bon, voilà, j’ai développé ce greffon pour pgModeler (C++/Qt), et j’ai envie de le partager dans une petite dépêche.
Mes motivations principales étaient de pouvoir effectuer des requêtes dans mon logiciel de modélisation préféré, bien entendu, et le fait que les logiciels de modélisation que je connais ne prennent pas en charge les jointures existantes ou automatiques.
Votre client SQL est cool ? Mais est‑il cool à ce point ?! :)
{kind=link}
Rapide présentation de pgModeler
pgModeler est un logiciel de modélisation de base de données. Bien que plutôt généraliste — si l’on s’en tient à un modèle logique des données — il est spécialisé PostgreSQL. Il permet entre autres de :
- construire par interface graphique un modèle de base de données (tables, schémas, rôles…), mais bien plus ; en fait, il propose toutes les fonctionnalités offertes par PostgreSQL, allant jusqu’aux extensions PostGIS ;
- créer une base de données à partir d’un modèle : passer de la représentation à l’implémentation ;
- à l’inverse, créer un modèle à partir d’une base de données ;
- comparer une instance PostgreSQL avec un modèle et produire — voire réintégrer — les différences entre schémas ;
- administrer sa base, avec un module riche, mais qui n’égalera sans doute pas pgAdmin ;
- produire un dictionnaire des données.
Des discussions sont en cours pour rendre pgModeler nativement compatible avec les autres systèmes de gestion de bases de données relationnelles (SGBDR) grâce à l’excellent extracto‑chargeur (ETL) pgLoader.
Présentation du requêteur graphique
Le requêteur graphique est un greffon pour pgModeler. La sortie officielle de ce greffon coïncide avec celle de la version 0.9.2 stable de pgModeler : c’est l’occasion de rappeler ces liens vers l’annonce officielle et la liste des changements.
Le requêteur graphique consiste en deux modules :
- le cœur, qui permet de construire des requêtes SQL à partir des entités graphiques du modèle – tables, colonnes et relations :
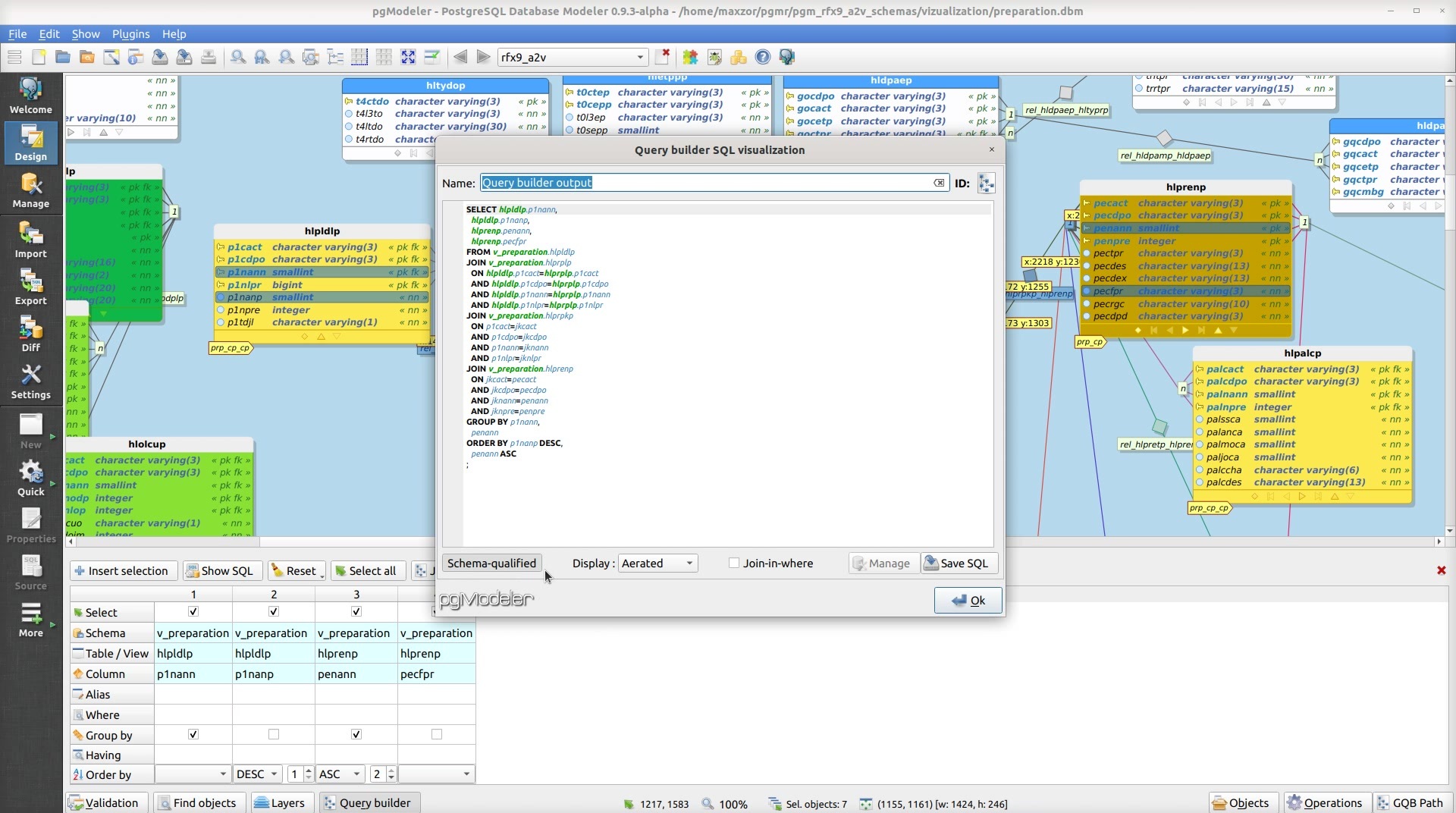
- le moteur d’inférence de jointures, qui, à partir de tables dans la clause
select, propose une liste de jointures complètes possibles, classées par coût total :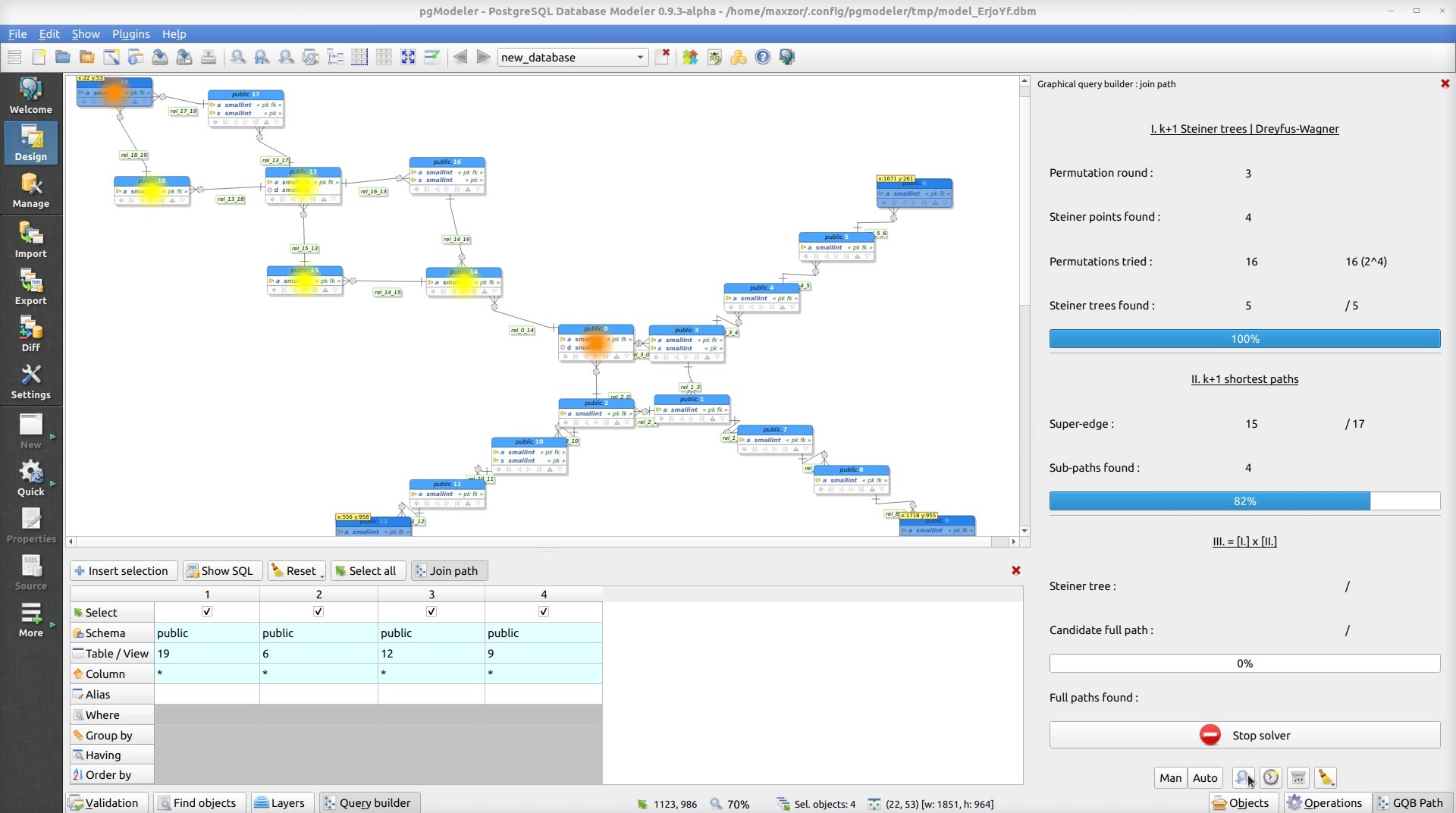
Alors que le cœur est très classique et n’apporte pas grand‑chose par rapport aux requêteurs graphiques de Microsoft Access, SQL Server Management Studio, pgAdmin 3 ou autres Active Query Builder d’Active Database Software… La partie solveur de jointures est plus intéressante et nous allons nous y attarder un peu ici.
Solveur de jointures
Une vidéo de présentation (en anglais) tout aussi complète que la section suivante est disponible ici. Le fichier README de GitHub (en anglais aussi) est aussi équivalent. La vidéo comporte en plus une partie guide d’utilisation.
Fonctionnement
Le solveur de jointures reçoit comme entrée un ensemble de tables à relier, et produit une liste de chemins valides, c’est‑à‑dire différentes façons de joindre ces tables. La liste des chemins potentiels est triée par coût ascendant. Il y a une pondération par défaut, et il est possible de personnaliser celle‑ci dans le menu paramètres du solveur.
Pendant la marche du solveur, un rapport d’avancement est affiché, et l’on peut arrêter le solveur s’il prend trop de temps. Il est aussi possible d’afficher en temps réel les tables inspectées (c’est le deuxième GIF du README du dépôt du greffon) et d’en apprendre plus sur l’algorithme. Parlons algorithmes justement !
Algorithmes
Ce greffon fait appel à différents algorithmes de graphes relativement simples. Pour le mode manuel (sans solveur), la construction de la requête a recours à un tri topologique, qui repose sur une implémentation du parcours en profondeur.
Pour le mode automatique (l’inférence), d’autres algorithmes entrent en jeu via les bibliothèques Boost et Paal :
- une découverte des tables connectées (via DFS) ;
- une recherche sur les arbres de Steiner dans le cas de trois tables ou plus à joindre ;
- un parcours des chemins les plus courts, via l’algorithme de Dijkstra notamment ;
- un tri topologique pour finir, comme dans le cas manuel.
Quelques bases algorithmiques sont posées, on peut pour la suite envisager des choses bien plus intéressantes ! Je pense aux réseaux de flot et au théorème flot‑max/coupe‑min pour les EXPLAIN ANALYZE, par exemple.
Bilan
Le solveur a plus un statut expérimental — c’était une stimulation intellectuelle sympathique dans sa conception — que celui d’une fonctionnalité mature et éprouvée. L’algorithmique est plus que perfectible. Mais c’est surtout son intérêt qui reste à valider, et vos retours sont les bienvenus :
- dans les modèles simples, la valeur ajoutée par rapport au mode manuel n’est pas énorme ;
- dans les modèles complexes, le nombre de résultats renvoyés par le solveur, surtout sans paramétrage personnalisé, peut devenir désarmant.
Une fonctionnalité qui pourrait aider pour ce dernier type de modèle est celle des calques multidimensionnels. Ces calques contournent la limitation historique des bases de données relationnelles « table n − 1 schéma » pour en faire « table n − n calque ». Cela permettrait de stocker des états fonctionnels, des catégories de traitements ou de requêtes, dans un ensemble visuel, etc., pour restreindre une exécution du solveur à un tel ensemble.
Conclusion
L’objectif initial de ce greffon était de ne plus avoir à se fader des select débiles. S’il peut servir à d’autres personnes, c’est bien… Et si les écoles pouvaient remplacer leurs Microsoft Access dégueulasses par pgModeler dans leurs cours de conception de bases de données, ça serait le rêve. :D
Ce greffon est en version plus ou moins bêta : il ne devrait plus planter grossièrement, mais de nombreuses corrections mineures et plus importantes restent à faire. Une liste des améliorations envisagées est disponible ici, à vos claviers !
Au moment de la publication de cette dépêche [28 janvier 2020], le requêteur est sur le point d’être intégré au dépôt officiel, mais ce n’est pas encore fait, il n’est donc pas encore distribué (binaires payants sur le site officiel, encore moins dans les dépôts des distributions). Je vous suggère pour compiler d’utiliser la branche 0.9.3‑alpha de pgModeler et la branche master de ma divergence des greffons.
Aller plus loin
- Site officiel de pgModeler (592 clics)
- Dépôt GitHub de pgModeler (90 clics)
- Dépôt GitHub du greffon de requêtage graphique (117 clics)
- Cui‑cui officiel (68 clics)
- Reddit (40 clics)
# questions dev
Posté par pralines . Évalué à 5.
merci de nous rappeler l'existence de ce modeler
juste par curiosité, tu as développé le greffon en c++/qt parce que pgModeler est aussi développé de cette façon ?
si oui, peux tu me dire si tu développes sous linux avec les outils de ta distribution ?
si oui, quelle distrib et quels outils, je m'y perd un peu dans les framework multiplateforme…
PS : actuellement, je me remet doucement à Delphi sous windows et Lazarus sous linux (car delphi linux pas dispo en édition communautaire)
Envoyé depuis mon Archlinux
[^] # Re: questions dev
Posté par Maxzor . Évalué à 4. Dernière modification le 30 janvier 2020 à 09:44.
Oui. Il y a un an j'avais fait une pull request pour intégrer le requêteur directement dans pgModeler… mais la dépendance à Boost a fait préférer l'approche greffon.
J'utilise un ubuntu de base et les qt5 et qtcreator empaquetés… un peu de atom… même si j'essaie de me mettre uniquement à vim. Peut-être qu'avec Qt6 et CMake ça ira mieux niveau IDEs! Aujourd'hui il n'est pas facile/possible de développer pgModeler sous windows, question visual studio+qmake.
Si tu cherches à faire du c++, ne prends pas le code que j'ai écrit comme une référence… je me considère comme débutant et il est avec le recul encore pas mal sale :)
Je ne connais pas du tout le Pascal et suis curieux.
[^] # Re: questions dev
Posté par pralines . Évalué à 5.
le Pascal est considéré comme un langage adapté aux débutants, il était enseigné aux non informaticiens lorsque j'étais en fac de sciences (époque très lointaine…)
mais ce que j'aime surtout dans Lazarus et Delphi (et C++ Builder), c'est l'IDE pour développer très rapidement des applications graphiques sans avoir à apprendre l'api du toolkit graphique : on dessine son interface avec la souris, on double-clique sur un bouton et on n'a plus qu'à écrire le code qui devra être exécuter au déclenchement de l'évènement choisi
l'exécution du programme se fait directement dans l'IDE après une compilation qui se fait en mémoire : le débutant peut immédiatement voir le résultat (ou les erreurs :-)
Envoyé depuis mon Archlinux
[^] # Re: questions dev
Posté par Maxzor . Évalué à 3.
J'imagine que c'est commun à un certain nombre de frameworks GUI, dans QtCreator on peux composer et agencer par glisser/déplacer les widgets et un compilateur tranforme ton design en header.
Il est aussi possible, pour les traitements triviaux, de lier des événements pré-conçus (le système signal/slot de Qt) entre eux depuis l'interface graphique.
Par contre l'exécution à la React ça m'intéresse… même si la compilation incrémentielle fait peu de différence je trouve au final.
[^] # Re: questions dev
Posté par yabb85 . Évalué à 3.
Attention le côté sexy du lancement dans l'ide des produits Borland a un gros point noir, celui d'avoir besoin de l'ide pour tourner. Ou alors se prendre la tête pour intégrer les dépendances dans le binaire. Mais les designers de qt ne font pas la même chose. Les ide Borland permettent de développer une application entière sans avoir besoin de coder vraiment. Juste un clic sur le bouton de la ui ouvre un fichier dans lequel on rajoute uniquement le code de la fonction et il fera automatiquement le code qui sert a appeler cette fonction. Je l'ai utilisé par le passé. C'est très (trop) simple a utiliser mais on ne comprend pas vraiment ce que l'on fait. Surtout si le but est de faire un binaire portable.
[^] # Re: questions dev
Posté par pralines . Évalué à 4. Dernière modification le 31 janvier 2020 à 08:47.
c'est vrai que j'ai été étonné de ne pas voir d'outil pour générer un install.exe
je n'ai pas encore vrai de vrai programme avec la version 10 de Delphi, mais les premiers tests généraient un exécutable autonome (fonctionnant sur un poste non équipé de l'IDE)
il faut que je réalise un petit projet avec d'autres composants visuels afin de vérifier si l'IDE produit encore un exécutable autonome…
et je dois aussi d'arrêter de faire la publicité d'un outil non libre ici….
et plutôt parler de Lazarus :-)
Envoyé depuis mon Archlinux
# Reflex ? ;-)
Posté par klain15 . Évalué à 4.
Je reconnais la structure de la base de données Reflex….. ;-)
Avec toutes ses particularités (dates sur 4 colonnes, noms de colonnes sur 6 caractères et noms de tables sur 7 caractères, …).
Je suis par contre surpris de voir que vous avez cette base de données hébergée sur PostgreSQL car elle est normalement proposée que sur Oracle ou SQL Server.
Comment avez-vous fait ?
[^] # Re: Reflex ? ;-)
Posté par Maxzor . Évalué à 4. Dernière modification le 01 février 2020 à 15:38.
Bonjour,
Perspicace!
Je travaille pour un intégrateur, Hardis communique sur sa base, à l'extérieur, sous forme de dictionnaire html ou de VMs de formation. J'ai passé une base v8/9 sqlserver de ma VM par ETL (pgLoader/ du sed à la main) vers postgres. J'ai recréé de façon semi-automatique 4k relations, (tu dois savoir que les instances reflex sont des fichiers plats sans clé étrangère) et hop :)
Je rêverais de mettre le modèle sur une instance SCM publique pour que les divers archis, DBAs, consultants et clients l'améliorent et s'échangent des requêtes, c'est la façon dont on travaille au XXIème siècle… mais mon employeur me l'a formellement interdit et pas envie de me retrouver flanqué d'un procès.
[^] # Re: Reflex ? ;-)
Posté par bobert . Évalué à 2. Dernière modification le 07 février 2020 à 14:48.
Merci beaucoup à Maxzor pour ce greffon !
De quelle base de données Reflex parle-t-on ? De celle-ci…?
[^] # Re: Reflex ? ;-)
Posté par Maxzor . Évalué à 2. Dernière modification le 07 février 2020 à 16:57.
Moins noble, moins noble, celle-là :
https://www.reflex-logistics.com/
Suivre le flux des commentaires
Note : les commentaires appartiennent à celles et ceux qui les ont postés. Nous n’en sommes pas responsables.