
La sortie de Pandas 0.24.1 est l’occasion de parler de Python et du traitement des données scientifiques. Depuis quelques années, un certain nombre de projets ont émergé afin d’équiper Python pour les mondes de la recherche. Cette dépêche présente quelques‐uns de ces projets. Des ressources pour aller plus loin sont proposées en fin de dépêche.
Sommaire
- SciPy
- Jupyter
- Pandas
- Scikit-learn
- Matplotlib
- Statsmodels
- Numpy
- Des compilateurs pour accélérer les traitements
SciPy
SciPy fournit un environnement de logiciels libres pour Python afin de faire des mathématiques, des sciences ou de l’ingénierie. En pratique, le terme « SciPy » fait référence à plusieurs entités :
- un écosystème de logiciels ;
- une communauté de personnes ;
- des conférences dédiées à Python et les sciences ;
- et enfin la bibliothèque SciPy, un composant de la couche SciPy qui fournit des routines pour les données numériques.
L’écosystème SciPy
Faire de la science informatisée avec Python repose sur un nombre restreint de paquets :
- NumPy, le module pour le calcul numérique, qui définit le tableau numérique, le type matrix et les opérations basiques qui leur sont associées ;
- La bibliothèque SciPy, une collection d’algorithmes numériques et des boîtes à outils spécifiques à des domaines tels que le traitement du signal, l’optimisation et les statistiques ;
- Matplotlib, un module abouti pour réaliser des graphiques qui fournit des fonctions pour produire des graphiques 2D adaptés à la publication et quelques fonctions pour les graphiques 3D.
L’écosystème SciPy repose sur cette base pour ensuite proposer des outils plus spécialisés. Un aperçu de quelques‐uns de ces outils est donné dans la suite de l’article.
Calculs et gestion des données
- pandas, qui fournit des structures de données simples à utiliser et performantes ;
- SymPy, pour faire des mathématiques symboliques et de l’algèbre computationnelle ;
- scikit-image, un ensemble d’algorithmes pour le traitement de l’image ;
- scikit-learn, un ensemble d’algorithmes et d’outils pour l’apprentissage automatique ;
- h5py et PyTables, qui permettent tout deux d’accéder à des données enregistrées au format HDF5 ; HDF5 est un modèle de données, une bibliothèque et un format de fichier pour enregistrer et gérer des données massives et complexes.
Productivité et calculs haute performance
- IPython, qui est une interface interactive et complète qui vous permet de facilement travailler vos données et d’essayer vos idées ;
- le carnet Jupyter, une application en mode serveur qui permet de créer des documents de code en direct, avec des équations, des visualisations et des explications ; les carnets facilitent la reproduction, la réutilisation et le partage de code, que ce soit au niveau d’une équipe de recherche, pour la publication scientifique ou dans le cadre d’un cours ;
- Cython, qui étend la syntaxe Python pour faciliter le développement d’extensions en C/C++ ;
- Dask, Joblib et IPyParallel, qui sont des modules Python pour distribuer le traitement des tâches ; ces modules sont orientés vers le traitement de données numériques.
Gestion de la qualité
- pytest, qui remplace progressivement le module non maintenu nose, est un environnement pour tester son code Python ;
- numpydoc, qui est une convention et une bibliothèque pour documenter du code Python scientifique.
Jupyter
Jupyter-notebook est une application Web libre (BSD 3 Clause License) qui permet de partager des documents contenant code, équations, visualisations et texte. Python n’est pas le seul langage géré, plus de quarante langages sont pris en charge, dont R et Scala.

Du point de vue de l’interface, il s’agit d’une console sous stéroïdes : on retrouve donc l’alternance entre des commandes et leurs sorties dans un environnement d’exécution. Le notebook de Jupyter ajoute à cela trois fonctionnalités majeures :
- la persistance de la session, ce qui permet de sauver toute une série de commandes et de la recharger ;
- l’édition et l’exécution de commandes par blocs ; le notebook se comporte ainsi comme un long script découpé en morceaux que l’on peut exécuter à la demande, ce qui est extrêmement utile pour des projets scientifiques exploratoires où l’on teste des idées à la chaîne ;
- la prise en charge de sorties graphiques comme des graphes, des images ou du texte mis en forme comme sur cet exemple. La bibliothèque Pandas présentée ci‐dessus ajoute aussi sa méthode de rendu pour mettre en forme les tableaux de données et faciliter la lecture.
Sur le plan technique, ce logiciel est découpé en trois parties : le serveur qui gère les sessions, les consoles (~onglets d’un terminal) qui affichent les blocs de code et leurs sorties, et enfin, pour chaque console, un noyau qui exécute les instructions dans un environnement persistant.
La conception du projet est volontairement modulable et facilite l’ajout de fonctionnalités via des extensions tierces, comme par exemple les méthodes de rendu pour les graphiques et les données.
Pandas
Pandas est une bibliothèque sous licence BSD pour manipuler et analyser des données. Elle permet de lire des tableaux provenant de différents types de fichiers (CSV, Excel, JSON), de filtrer des tableaux, de faire des extrapolations, des interpolations, de fusionner des tableaux de différentes manières. Pandas permet également de manipuler des données temporelles et des séries.
Il se combine idéalement avec iPython ou Jupyter afin de profiter d’un environnement dynamique pour développer des scripts. À noter qu’à partir de janvier 2019, les prochaines versions de Pandas ne fonctionneront qu’avec Python 3. Cette version est donc la dernière à fonctionner officiellement avec Python 2.7. Les versions 3.5, 3.6 et 3.7 sont aussi prises en compte. La liste des nouveautés et des corrections de cette nouvelle version est longue. Sans entrer dans les détails, voici les principales :
-
merge()permet maintenant de fusionner directement des objets du type DataFrame et Series sans passer par une conversion des objets Serie en DataFrame (GH21220) ; - ExcelWriter accepte dorénavant mode comme argument afin de permettre l’ajout à un workbook (? à vérifier) existant lors de l’utilisation d’openpyxl (GH3441) ;
- FrozenList s’est vu ajouter les méthodes
.union()et.difference(), cette fonctionnalité simplifie les groupby qui s’appuient explicitement sur l’exclusion de certaines colonnes — voir « Splitting an object into groups » pour davantage de précisions (GH15475, GH15506) ; -
DataFrame.to_parquet()permet d’avoir un index comme argument, afin que l’utilisateur puisse outrepasser le comportement par défaut du moteur pour inclure ou au contraire omettre les index du DataFrame dans le fichier Parquet produit (GH20768) ; -
DataFrame.corr()etSeries.corr()acceptent maintenant les appels pour les méthodes de calculs génériques des corrélations, comme l’intersection d’histogrammes (GH22684) ; -
DataFrame.to_string()accepte maintenant les décimaux comme argument, l’utilisateur peut spécifier quel séparateur décimal devra être utilisé dans la sortie (GH23614).
Quelques exemples de manipulation de données avec Pandas à partir du fichier tournagesdefilmsparis2011.csv :
import pandas as pd
datafile = "tournagesdefilmsparis2011.csv"
data = pd.read_csv(datafile, sep=";")
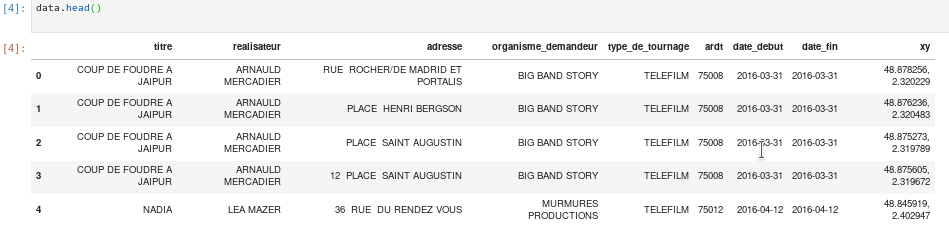
[5, 4]])data.head() affiche les premières lignes du DataFrame pandas.
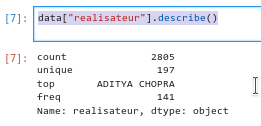
data["realisateur"].describe() permet de décrire à travers les opérations statistiques de base une catégorie. Ici, il s’agit d’une catégorie non numérique, describe ne peut faire réaliser les moyennes, quartiles et autres opérations de base.
Évidemment, une utilisation plus avancée de Pandas est possible. :) Il est possible de joindre plusieurs bases dans un dataframe avec la fonction merge() ou de procéder à manipuler les données avec des expressions rationnelles via replace().
Au niveau interopérabilité, des solutions existent pour enregistrer les dataframes de Pandas en fichier CSV, ODS ou Excel.
Scikit-learn
Scikit learn est une bibliothèque libre pour Python dédiée à l’apprentissage automatique. Elle est le plus souvent utilisée de pair avec Pandas, Matplotlib et les bibliothèques du projet SciPy. Scikit Learn fournit des fonctions pour analyser des données avec des algorithmes liés à l’apprentissage automatique (forêts aléatoires, régressions logistiques, algorithmes de classification et machines à vecteurs de support).
Matplotlib
Matplotlib est une bibliothèque pour réaliser des graphiques en 2D de qualité publication, dans une variété de formats de papier et d’environnements interactifs sur différentes plates‐formes. Matplotlib peut être utilisé dans les scripts Python, les interpréteurs de commandes Python et IPython, les carnets Jupyter et les serveurs d’applications Web.
Matplotlib essaie de rendre les choses faciles et les choses difficiles possibles. Il vous aide à produire des graphiques, des histogrammes, des spectres de puissance, des diagrammes à barres, des diagrammes d’erreurs, des diagrammes de dispersion. Pour des exemples, voir ceux de la galerie.
Les graphiques qui sont présentés dans cet article ont été réalisés avec Matplotlib.
Statsmodels
statsmodels est un module Python qui fournit des classes et des fonctions pour réaliser les estimations issues de nombreux modèles statistiques (comme ANOVA ou MANOVA, par exemple), faire des tests statistiques et explorer des données statistiques. Une liste exhaustive de statistiques sur les résultats est disponible pour chaque estimateur. Les résultats sont testés par rapport aux progiciels statistiques existants pour s’assurer qu’ils sont corrects.
Numpy
Numpy est la bibliothèque de référence pour le calcul numérique en Python. La plupart des projets scientifiques s’appuient dessus et de nombreuses bibliothèques sont compatibles avec ce projet.
La bibliothèque Numpy sert à résoudre deux problèmes principaux :
- stocker « en mémoire » et accéder à des données structurées en tableaux ;
- effectuer des opérations algébriques de base sur ces données.
Pour ce faire, Numpy propose un type np.ndarray pour représenter des tableaux de données multidimensionnelles. Ces données sont accessibles facilement par indexation ou par tranches :
>>> import numpy as np
>>>
>>> data = np.array([[1, 2, 3],
... [4, 5, 6]])
>>> print(data[0, :]) # première ligne
array([1, 2, 3])
>>> print(data[:, 1]) # deuxième colonne
array([2, 5])
>>> data[:, [1, 0]] # réindexation des colonnes
array([[2, 1],
[5, 4]])Une multitude d’opérations de base sont disponibles : addition, produit, transposition, etc. Leur implémentation est souvent extrêmement efficace afin de minimiser le temps de calcul et l’empreinte en mémoire. L’efficacité de ces opérations repose en grande partie sur le fait que les données à traiter sont d’un type prédéfini (ex. : entier int32 ou flottant float64) et stockées de manière contiguë, ce qui permet d’optimiser les boucles d’opérations et d’utiliser des instructions vectorisées. Le code critique est d’ailleurs rarement écrit en Python : des bibliothèques de liaison (bindings) vers des bibliothèques écrites en C, Fortran ou assembleur sont souvent utilisées (openblas, intel-mkl).
Tout en étant assez étoffée en termes de fonctionnalités, l’interface de programmation reste plutôt simple et idiomatique, ce qui permet d’avoir un code compact et facile à comprendre. On notera en particulier la surcharge des opérateurs sur les objets np.ndarray qui donne ainsi accès à l’addition, la soustraction, ou le produit terme à terme en respectant les conventions d’usage sur l’expansion des dimensions :
>>> data + np.array([[-1, -2, -3]]) + 1
array([[1, 1, 1],
[4, 4, 4]])Les autres opérations sont implémentées par une multitude de fonctions assez bien documentées dans l’ensemble, même si l’aspect didactique est légèrement moins soigné que pour Matlab.
Le champ d’application de Numpy se limite néanmoins aux opérations mathématiques élémentaires : on n’y trouvera donc pas de traitement du signal comme les convolutions 2D ou le filtrage ou la gestion du stockage des données sur disque, qui reste minimale.
Ce sont d’autres modules qui apportent ces fonctions supplémentaires, avec notamment une série de modules scikit-* développés en étroite collaboration avec NumPy : scikit-image, scikit-video, scikit-learn…
Des compilateurs pour accélérer les traitements
Python reste un langage interprété dont la conception ne favorise pas particulièrement la performance à l’exécution, en tout cas avec l’interpréteur standard CPython.
Ainsi, les traitements des données avec des boucles for et des embranchements if … then … else ne sont pas particulièrement rapides. Les possibilités de traitement parallèle sont par ailleurs assez faibles en raison de l’utilisation d’un verrou global pour se protéger des erreurs d’accès concurrent.
Il est donc parfois nécessaire d’aller plus loin dans la recherche de la performance que ce que NumPy propose par défaut. Considérons par exemple le code suivant :
def np_cos_norm(a, b):
val = np.sum(1. - np.cos(a-b))
return np.sqrt(val / 2. / a.shape[0])Il peut encore être accéléré en utilisant un des compilateurs pour Python (scientifique) qui existe. Chacun de ces compilateurs permet un gain plus ou moins grand en performance, et demande une modification plus ou moins intrusive du code, tout en imposant des contraintes de déploiement plus ou moins fortes.
Cython
Le code précédent s’écrirait en Cython :
# cython: boundscheck = False
# cython: wraparound = False
# cython: cdivision = True
cimport numpy as np
from libc.math cimport cos, sqrt
def np_cos_norm(np.ndarray[double, ndim=1] a, np.ndarray[double, ndim=1] b):
cdef unsigned i, n
cdef double val = 0., res
n = a.shape[0]
for i in range(n):
val += 1. - cos(a[i]-b[i])
res = sqrt(val / 2. / n)
return resCython se charge de traduire ce code en C, avec la possibilité (vérifiable avec le mode cython -a) de donner assez d’information au compilateur pour que les parties gourmandes en calcul ne fassent aucun appel à l’environnement d’exécution C. Ce code C est ensuite compilable en un module dynamique classique.
D’un point de vue langage, on notera les commentaires en début de fichier qui permettent au compilateur de faire des hypothèses supplémentaires lors de la génération de code. Plusieurs mots clefs (cdef, cimport…) viennent étendre le langage et indiquer au compilateur les identifiants appartenant au monde natif et celles (les autres) appartenant au monde interprété.
Numba
Le code précédent s’écrirait en Numba :
from numba import jit
@jit
def np_cos_norm(a, b):
n = a.shape[0]
for i in range(n):
val += 1. - cos(a[i]-b[i])
return sqrt(val / 2. / n)Numba va dériver à l’execution une version statique de cette fonction, la compiler à la volée et utiliser le noyau généré en lieu et place de la fonction d’origine.
La compilation en code natif repose sur LLVM, et des options peuvent être passées au compilateur à travers des arguments du décorateur, p. ex. @jit(nopython=True) pour déclencher une erreur si la traduction en code natif ne faisant pas référence à l’API Python a échoué. Un cache évite de relancer cette compilation à chaque appel.
Pythran
Le code précédent s’écrirait en Pythran :
# pythran export np_cos_norm(float64[], float64[])
def np_cos_norm(a, b):
val = np.sum(1. - np.cos(a-b))
return np.sqrt(val / 2. / a.shape[0])Le compilateur Pythran va traduire ce code en un module natif avec la garantie qu’aucun appel interprété ne sera fait pour exécuter le corps de la fonction np_cos_norm.
La compilation se fait en avance de phase à travers pythran mon_module.py. Il est possible de contrôler finement le processus de compilation en passant des drapeaux de compilations spécifiques : -Ofast, -march=native, voire de générer du code SIMD avec -DUSE_XSIMD.
Les logiciels à base de graphes de calculs : Tensorflow, Pytorch, etc.
Conçus à l’origine pour faciliter le travail sur les réseaux de neurones, il serait dommage de sous‐estimer les autres usages possibles des bibliothèques Tensorflow ou PyTorch et anciennement Theano.
Ces bibliothèques permettent de définir des algorithmes sous la forme d’un graphe d’opérations symboliques défini très naturellement. L’exemple ci‐dessous démontre qu’il s’agit quasiment du même code qu’avec Numpy. Ce graphe est ensuite optimisé puis compilé pour une exécution rapide sur processeur central ou graphique.
Les moyens importants alloués au développement de ces projets assurent un excellent support, un haut niveau d’optimisation et une documentation d’assez bonne qualité complétée par d’innombrables tutoriels.
def tf_cos_norm(a, b):
val = tf.reduce_sum(1. - tf.cos(a-b))
return tf.sqrt(val / 2. / tf.cast(a.shape[0], 'float32'))
a = tf.placeholder(dtype='float32', shape=[4])
b = tf.placeholder(dtype='float32', shape=[4])
y = tf_cos_norm(a, b) # résultat symbolique
with tf.Session() as sess:
y_eval = sess.run(
y,
feed_dict={
a: [1, 2, 3, 4],
b: [4, 3, 2, 1]
})Accessoirement, si l’on peut dire, ces logiciels offrent la différentiation automatique, c’est‐à‐dire que pour un graphe de calculs donné, on peut réclamer la dérivée d’une grandeur à l’un des nœuds en fonction d’une autre.
Aller plus loin
- Pandas 0.24.0 est sorti (120 clics)
- Matplotlib pour les représentations visuelles (106 clics)
- SciPy, Python pour les sciences (97 clics)
- Statsmodels, pour les statistiques (101 clics)
- Jupyter pour expérimenter et partager (110 clics)
- Seaborn, pour faire de jolis graphiques (165 clics)
- Numpy, pour les tableaux (117 clics)
- Scikit learn, pour le marchine learning (88 clics)
# Jupyter
Posté par Colin Pitrat (site web personnel) . Évalué à 10.
Alors, j'aime bien Jupyter et compagnie, mais quand je lis:
ça me fait bondir. C'est là l'inconvénient majeur des carnets, pas leur avantage. Pour le partage et la réutilisation de code, ce qui est bien c'est une librairie hébergée dans un repository publique (GitHub, gitlab, etc …)
De ce côté là, les carnets favorisent les mauvaises pratiques: copier-coller, absence de tests, exécution dans le désordre, versioning anarchique …
Les carnets c'est génial pour expérimenter, visualiser et manipuler des données et collaborer dans ce genre de travail. Et c'est super, pas la peine d'essayer de vendre des qualités qu'ils n'ont pas ! Une fois qu'on a clarifié ce qu'on veut faire, et qu'on veut partager son code, on crée une librairie dans un VCS et on écrit de la doc et des tests.
[^] # Re: Jupyter
Posté par lejocelyn (site web personnel) . Évalué à 7.
Je suis d'accord qu'en pratique, les carnets peuvent pousser, voire facilite, la production du code de mauvaise qualité.
Cependant, dans le principe, si le développeur se contraint à une écriture propre et documentée, les carnets facilitent également la production de codes réutilisables et documentés. Au niveau pédagogique, comme apprenant, j'ai suivi des cours qui étaient réalisés avec des carnets Jupyter, et j'ai trouvé ça très pratique. J'imagine que le professeur avait dû passer pas mal de temps à structurer son code et à le documenter par contre. Je me demande ce que ça peut donner pour faire une présentation, je n'ai pas encore utilisé les exports PDF disponibles.
De mon côté, je n'utilise pas Jupyter pour développer des scripts complexes ou du code logiciel, mais uniquement pour faire des analyses de mes données informatisées. Et pour cette tâche, ça aide énormément et les qualités que j'ai avancées sont au rendez-vous. Mais c'est vrai que pour développer du code plus algorithmique, je n'ai pas essayé, et en fait, je n'en vois pas vraiment l'intérêt. C'est sûrement que dans mon cadre d'utilisation pour la recherche, le code que je mets en place pour faire mes analyses n'est pas très complexe. Et dès que ça commence à être complexe, j'en fais un module que je développe via mon éditeur de code préféré.
[^] # Re: Jupyter
Posté par Bruno (Mastodon) . Évalué à 4. Dernière modification le 19 février 2019 à 09:40.
Je pense que ce que l'auteur de la dépêche a voulu dire c'est que les Notebooks sont intéressants pour "montrer" le code qui permet d'obtenir un résultat, et ceci de façon didactique et interactive.
Cela ne se substitue pas au repository et autres documentations et surtout pas au éditeurs intégrés pour les projets complexes.
[^] # Re: Jupyter
Posté par nlgranger . Évalué à 4.
Les carnets sont compréhensibles à la première lecture sans avoir à déchiffrer le code, ce qui permet de mettre l'emphase sur l'aspect explicatif ou pédagogique.
Ils servent d'exemples ou de tutoriaux interactifs: https://pytorch.org/tutorials/beginner/blitz/tensor_tutorial.html#sphx-glr-beginner-blitz-tensor-tutorial-py
Ils sont faciles à modifier, on peux itérer dans les modifications grâce à l'exécution dans le désordre, consulter ponctuellement une valeur, etc. Je m'en suis donc servi pour faire un TP récemment: https://github.com/nlgranger/hybrid_NN_HMM/blob/master/hybrid_NN_HMM.ipynb
Pour les sciences, le fait de mélanger code et sorties est idéal, on peut étudier à la volée un modèle ou des données. C'est donc toujours appréciable quand quelqu'un partage un notebook déjà structuré pour faciliter ce travail.
Quant à la mise en ligne, c'est à la discrétion de l'auteur, on peut partager des notebooks aussi facilement que du code.
# Outils complémentaires
Posté par freejeff . Évalué à 9.
Super dépêche qui permet d'appréhender rapidement l'écosystème python pour le traitement de données. Je rajouterais volontiers en complément à Matplotlib le module mlab de mayavi qui permet de manipuler des donner 3D bien plus facilement qu'avec Matplotlib. Je trouve également qu'en complément de scikit-image simple-itk est un super outil qui permet en plus de faire du recalage d'images de manière très simple, ce que ne fait pas encore scikit-image. On peut aussi rappeler qu'il existe dans le module scipy, le module ndimage, qui permet de faire des opérations sur des données ND (fonctionne donc pour la 3D). Il existe aussi une très bonne interface à OpenCV en python, qui est extrêmement performante, il y a en général un gain notable par rapport à scikit-image.
Il n'y a pas que du traitement de données en sciences, il y a aussi l'obtention des données par exemple. Il y a pas mal d'outils pour faire cela sous python. De manière générale, le site pypi est souvent d'une grande aide, lorsque l'on a un nouveau capteur, il est souvent intéressant de faire un tour sur ce site avant de se lancer dans la création de son propre binding !
Pour ceux qui sont intéressés par l'acquisition et le pilotage de machines sous python, vous pouvez regarder du coté de crappy développé depuis plusieurs années dans notre labo. Si je me motive, j'en ferais une dépêche un de ces jours.
[^] # Re: Outils complémentaires
Posté par barmic . Évalué à 6.
Il y a quelques temps au lieu d'utiliser matplotlib, j'avais utilisé pygal qui a des rendus assez jolis je trouve (et qui génère du svg de base c'est assez pratique pour moi).
[^] # Re: Outils complémentaires
Posté par Albert_ . Évalué à 7.
Matplotlib supporte le svg enfin cela depend du backend utilise.
Te cree un svg a la sortie avec le backend par defaut.
[^] # Re: Outils complémentaires
Posté par Albert_ . Évalué à 4.
En ce qui concerne mayavi, j'ai un peu l'impression que le projet est mort non?
Ce qui manque pour la 3D c'est l'inclusion d'un backend 3D dans Jupyter mais la cela demande un backend Vtk et une lib, comme mlab, qui prenne cela en compte.
Maintenant ca fait longtemps que je n'ai pas regarde l'etat de la 3D dans jupyter donc je suis probablement has been :)
[^] # Re: Outils complémentaires
Posté par freejeff . Évalué à 3. Dernière modification le 19 février 2019 à 13:30.
Je n'utilise pas trop jupyter, mais il semble que mlab est compatabile. Après, il faut voir à l'usage, mais comme c'est basé sur des technos webgl, il y a moyen que ça se passe bien …
En ce qui concerne Mayavi la dernière version semble dater de août 2018, ce qui n'est pas si mal, non ?
[^] # Re: Outils complémentaires
Posté par Albert_ . Évalué à 4. Dernière modification le 19 février 2019 à 13:58.
Et ils sont passes a python 3. Je connais des copains qui vont/sont contents :) et il y a en effet un support jupyter notebook. Genial. Il va falloir que je regarde ca.
J'avais dis que je n'avais pas suivit depuis quelques temps :)
[^] # Re: Outils complémentaires
Posté par glyg . Évalué à 2.
Salut,
Je n'ai pas regardé mayavi depuis longtemps, mais pour la 3D j'utilise ipyvolume qui fournis une couche python pour appeler threejs, sous forme de widget jupyter. Toujours sur les aspects 3D, ITK/VTK étaient super à la traîne mais depuis peu (quelques mois?) sont passés en python 3 et il existe une interface pour les carnets jupyter.
Merci lejocelyn pour la dépêche!
# Python as a Service
Posté par barmic . Évalué à 4.
Cet écosystème est aussi mis à disposition comme service par certains cloud providers. La partie machine learning d'Azure met à disposition NumPy, Pandas et IPython (au moins) pour manipuler les données et Google permet l'intéraction entre BigQuery et cet environnement.
[^] # Re: Python as a Service
Posté par Bruno (Mastodon) . Évalué à 7.
C'est exact , j'ajouterai que OBS (Orange Business service ) et OVH (https://www.ovh.com/fr/cloud/apps/jupyter.xml) le font aussi. (pas de raison de faire de la pub que pour Microsoft et Google ;-)
# Autre bindings c++ : cppyy
Posté par qpad . Évalué à 10.
Merci pour cette dépêche !
Pour ceux que ça intéresse je voulais aussi signaler cppyy qui permet de réaliser des bindings C++ de façon extrêmement simple.
Juste un exemple extrait de la doc :
C'est par exemple ce qui est utilisé pour utiliser les librairies C++ ROOT avec python (ROOT est un système complet d'analyse numérique très utilisé en physique des hautes énergies et développé au CERN )
# ça peut aussi servir
Posté par tao popus . Évalué à 6.
PYO est un module python dédié au traitement de signal.
http://ajaxsoundstudio.com/software/pyo/
Il est notamment utilisé par différents outils de traitement du son et de musique, comme Cecilia par exemple :
http://ajaxsoundstudio.com/software/cecilia/
# SPYDER
Posté par binoyte . Évalué à 4.
Spyder aussi est bien pratique pour ceux qui veulent un environnement à la Matlab, Scilab, Octave etc…
Il peut fonctionner aussi en cellule comme Jupyter.
Suivre le flux des commentaires
Note : les commentaires appartiennent à celles et ceux qui les ont postés. Nous n’en sommes pas responsables.